NameList 筛选工具
https://xuanru.xyz
用户名密码我ins发你
Industries
这部分可以根据行业来调研公司, 你可以进入到某一个行业, 点开始研究, 这个过程会比较长, 耐心等待, 一次research要持续几分钟, research的过程不要刷新。
目前的筛选用户逻辑
DISCOVER — 发现候选公司
两条路并行执行(Promise.all):
[LLM] AI知识生成
第一轮:大模型根据行业+地区的prompt生成30-40家公司。Prompt明确要求两类目标:
- Category A(行业终端客户,20-25家):该行业内有AI/GPU算力需求的中型公司,100-10000人,是核心目标。要求包含中国公司。
- Category B(新兴AI公司,10-15家):专门服务该行业的AI原生创业公司,必须有明确的行业聚焦,通用AI平台公司不算。
Prompt排除:世界500强、10000+员工、CSP/超大规模、顶级AI实验室(OpenAI/Anthropic/DeepMind等)、IT咨询公司、纯分销商/炒货商。每个行业有专门的mid-tier定义(比如Manufacturing就是工业IoT、
预测性维护、CV质检、数字孪生创业公司,排除Fortune 500制造商和国企重工)。
第二轮补充:把第一轮的公司名列表给LLM,要求从6个角度找遗漏——直接竞争对手、邻近子赛道、不同地区(尤其中国/东南亚/中东)、供应链上下游、2020年后成立的新公司、垂直行业AI模型公司。
两轮结果都过tier1 blocklist(硬编码的大公司名单,BAT、三大运营商、FAANG等),包含在里面的直接删除, 符合姐姐要求的腰部企业。
[Search] 信号搜索发现
根据行业生成25+条Tavily搜索查询,中英双语,覆盖:
- 算力部署信号:搜"GPU集群""推理服务器""AI算力""智算中心"
- 招聘信号:搜"算法工程师""推理部署""ML infrastructure""inference engineer"
- 融资信号:搜AI创业公司拿钱买算力的新闻
- 行业报告:搜行业AI公司名单/排行榜
- 供应商生态:搜谁在用NVIDIA/AMD/Intel的GPU
- 会议信号:搜GTC、AI Summit、NVIDIA Inception的参会公司
- 子赛道:取该行业前2个子赛道单独搜
- 边缘推理:搜"edge inference""on-device AI"
- 创业公司榜单:搜"AI startups to watch"
- 加速器信号:搜YC/Techstars/NVIDIA Inception出来的公司
- 创业数据库:搜Crunchbase、Tracxn的公开页面
- LinkedIn公司页面和招聘信息
- 采购/部署公告:国际搜PR Newswire的GPU采购公告,中国搜招标网
- 跨行业GPU基础设施:不限行业,搜任何自建GPU集群的公司
每条查询取5个结果,URL去重后拼成搜索上下文。
然后LLM从这些搜索结果中提取公司。提取prompt要求:只取tier2和tier3,必须和目标行业有关联(非AI&Technology行业时排除旷视/商汤/第四范式/MiniMax等通用AI公司),宁可多提取让后续步骤筛。
合并:两个池子按公司名标准化(去法律后缀、特殊字符)+Jaccard相似度(阈值0.6)+ 同国家去重。重叠的公司补充缺失字段(website、employeeCount、aiUseCases等),confidence取两边最大值。
EXTRACT — 清洗验证
校验每个候选人的数据是不是完整(name、country必填,其他字段可选),不合格的静默跳过。
DEDUPLICATE — 去重+过滤
三层过滤:
名称去重:标准化公司名(转小写、去法律后缀Corp/Inc/Ltd/GmbH等、去括号内容)后,同国家内相似度太高的合并。
Tier1硬过滤:所有tier字段为"tier1"的公司直接删除。这是blocklist之外的第二道防线——即使LLM没给tier1标签但blocklist没覆盖到,这里也会拦住, 避免加入新闻太多的大公司。
跨Run去重:查数据库中该行业已有的公司,用同样的标准化+相似度匹配,已存在的跳过,避免重复花搜索费。
如果候选人数超过limit,用diversity select:按(地区, 公司类型)分桶,桶内按tier2→tier3→tier1排序,然后轮询取。tier1最多占10%名额。
SCREEN — 预筛选
LLM快速过一遍所有候选人,决定哪些值得往下走(每个公司后续要花搜索费验证)。输入是精简的公司信息(名字、国家、tier、类型、AI信号、来源)。
判断规则按优先级:
- Rule 0:source=search的必留。这些公司是从GPU/AI基础设施相关搜索中发现的,出现在搜索结果本身就是AI相关性的证据。
- Rule 1:AI和inference字段都为null、不是emerging_ai类型、不是search来源、LLM也不认识它有AI基础设施的→删除。
- Rule 2:CSP/超大规模/顶级AI实验室/IT咨询→删除。在AI&Technology行业下,MiniMax/Moonshot/旷视/商汤等是目标→保留。在其他行业下,这些通用AI平台公司→删除(它们属于AI&Technology行业)。
- Rule 3:纯分销商/渠道商→删除。
- Rule 4:行业巨头/家喻户晓的大公司→删除(它们直接从NVIDIA/Cisco/Arista买,不是我们的客户)。
每个行业有专门的KEEP/DROP提示(比如Manufacturing:KEEP工业IoT、预测性维护、CV质检;删除 Fortune 500制造商、国企重工)。
CROSS-VERIFY — 搜索验证
对每家公司做Tavily搜索验证它是否真实存在且有AI相关性。5并发,200ms间隔。
搜索策略三级fallback:
- 主搜索:"公司名" "行业名" AI OR GPU OR "machine learning" OR NVIDIA(取10条)
- 如果0结果:去掉行业名再搜
- 还是0结果:只搜公司名(至少确认它存在)
搜索前先清理公司名(去法律后缀、括号、特殊字符),短名字(≤6字符)加行业名避免歧义。
LLM拿到搜索结果后判断:
- verified=true/false:公司是否在该行业有AI相关性
- confidence:0-1的置信度
- 顺便提取NVIDIA关系(partner/customer/unknown)和证据
通过条件(满足任一即可):
- LLM判定合格
- confidence ≥ 0.2
- 搜索结果 ≥ 3条(有足够多的网页提到它,说明公司是真的)
- search来源的公司,搜索结果 ≥ 1条就过(它本来就是从搜索中发现的,门槛更低)
LLM调用失败时的fallback:
- search来源的公司:只要有1条搜索结果就保留,置信度0.5
- 其他公司:需要至少2条搜索结果才保留,置信度0.4
不满足以上任何条件的→淘汰。
ENRICH — 补充AI信号
对通过验证但aiUseCases字段为空的公司,额外做一次搜索,专门找它的AI使用场景。补充后更新aiUseCases和inferenceWorkloads字段。已有AI信号的公司跳过。
NVIDIA CHECK — NVIDIA关系判定
先看cross-verify阶段收集的搜索结果里有没有NVIDIA相关内容(搜"nvidia""dgx""a100""h100")。如果有2+条提到NVIDIA,就复用这些结果,不再花钱搜。
如果cross-verify已经判定了NVIDIA关系(partner或customer),直接用,不再搜。
否则做专门搜索:"公司名" NVIDIA partner OR customer OR deployment OR GPU,取10条。
LLM根据搜索结果判定:
- partner:有正式合作伙伴关系的证据(NVIDIA Partner Network、Inception、ISV partner等)
- customer:在用NVIDIA产品(买了GPU/DGX/用CUDA/TensorRT),但没有正式伙伴关系
- unknown:证据不足
关键区分:出现在nvidia.com上不等于partner,可能只是案例或新闻。买GPU = customer不是partner。模糊时倾向customer。
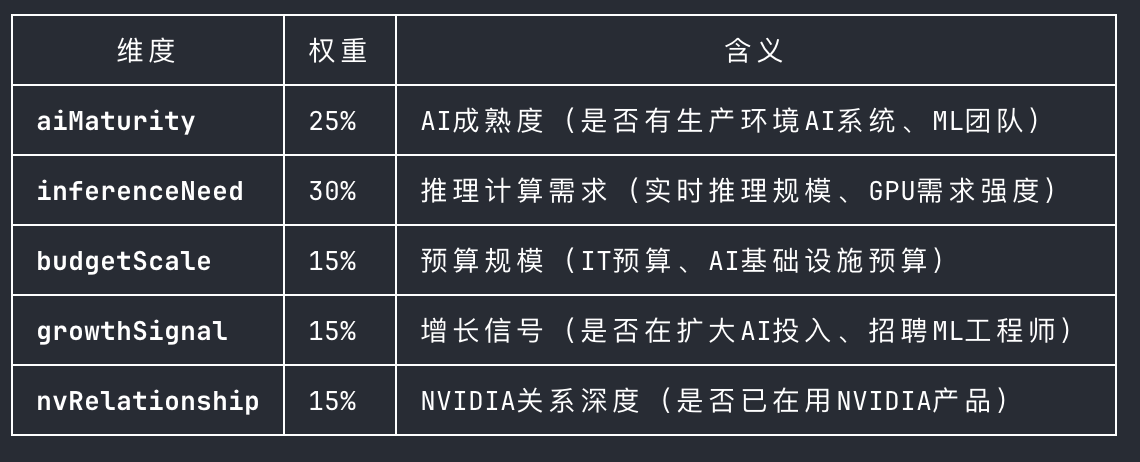
ASSESS — 优先级评估
LLM对每家公司5个维度打分(1-5分),加权计算总分:
- AI成熟度(25%):已经在跑AI推理工作负载?还是刚开始探索?
- 推理需求(30%):需要多大规模的GPU算力?推理类型是什么?权重最高因为这直接决定它需不需要买网络设备。
- 预算规模(15%):公司买得起网络设备吗?
- 增长信号(15%):融资、招聘、扩张等信号
- 进入机会(15%):是否已经有固定供应商?我们有没有机会切入?
search来源的公司,prompt里额外提示"这家公司是从GPU/AI基础设施搜索中发现的,有实际网络证据支持,未知字段至少给3-4分"。
总分映射:≥3.5 = high,≥2.5 = medium,<2.5 = low。
LLM同时输出一段summary说明推荐理由和一段notes记录关键发现。
PERSIST — 持久化
国家名标准化:USA/US→United States,UK→United Kingdom,Korea→South Korea等。
地区映射:根据标准化后的国家名映射到region(United
States→na,China→apac,Germany→europe,Singapore→sea,Israel→middle-east等)。覆盖100+国家。如果国家名匹配不上,再试LLM返回的region字符串,最后fallback到研究任务的region。
写入逻辑:
- 按公司名+国家查DB,已存在的→更新(补充缺失字段,不覆盖已有值)
- 不存在的→新建
- starred的公司→数据不覆盖(只追加新source),保护人工标注
属性说明
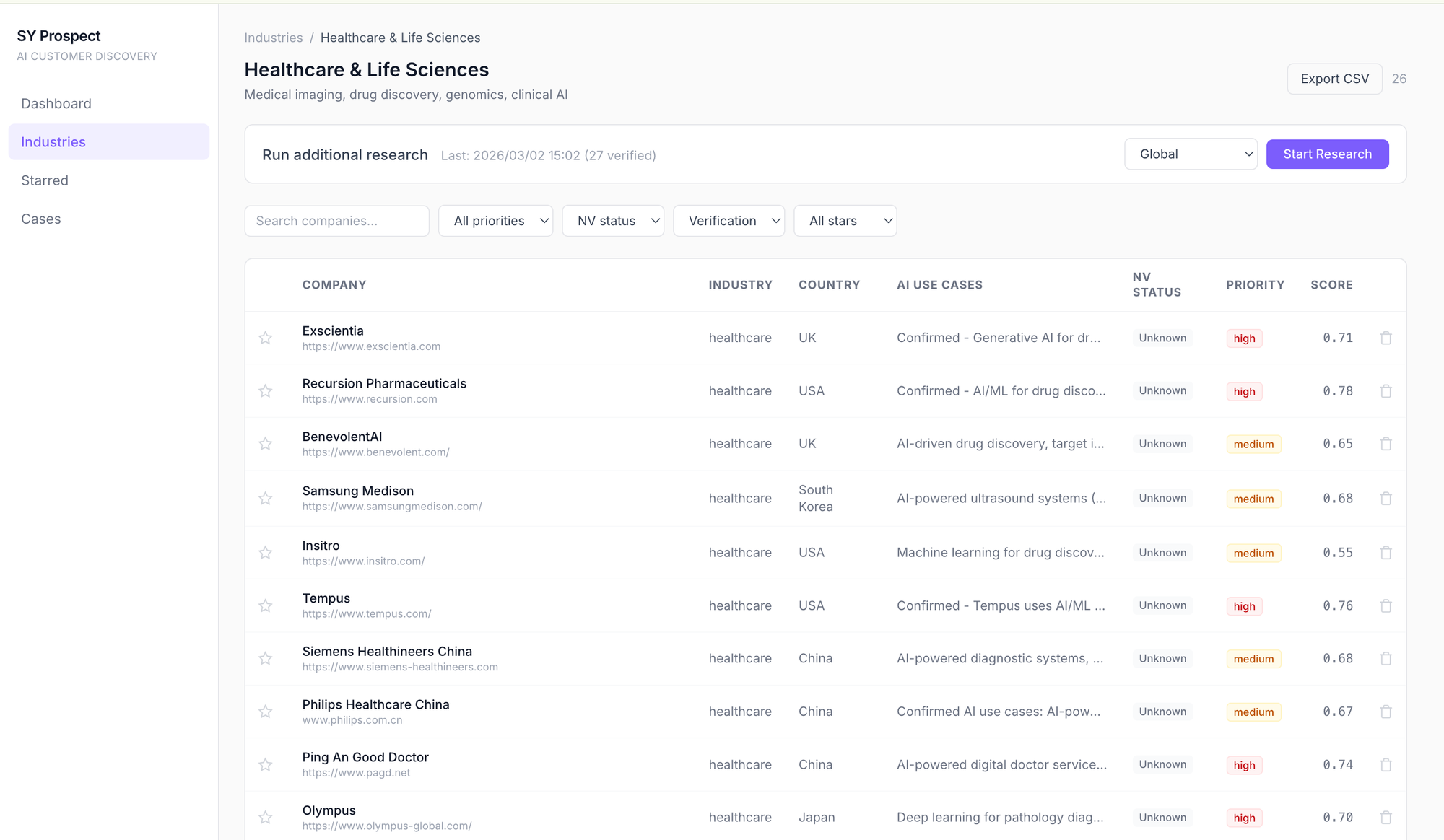
COMPANY (公司)
- 公司名称 + 网站URL,来自数据库 companies.name 和 companies.website
INDUSTRY (行业)
- 公司所属行业分类,如 healthcare,关联到 industries 表
COUNTRY (国家)
- 公司所在国家。也用于去重逻辑——同名公司在不同国家视为不同实体
AI USE CASES (AI应用场景)
- 描述公司如何使用AI的文本,由 AI 研究 pipeline 的 extraction 步骤自动生成
- 例如 "Generative AI for drug discovery"、"Deep learning for pathology diagnosis" 等
NV STATUS (NVIDIA 关系状态)
- 4种状态:partner(合作伙伴) / customer(客户) / prospect(潜在客户) / unknown(未知)
- 由 pipeline 的 nvidia-check 步骤自动检测,也可手动下拉修改
- 默认值为 unknown
PRIORITY (优先级)
- 3档:high / medium / low
- 由 SCORE 的阈值决定:
- 0.45 ~ 0.70 → medium
- < 0.45 → low
- 0.70 → high
SCORE (优先级评分)
- 0.0 ~ 1.0 的加权平均分,由 AI 评估 5 个维度算出(src/ 中的 assess.ts):
Detail
你可以点击任何一家公司, 去看这个公司的信息, 优先度最高的公司会标绿色底色
其他操作
- 你可以星标一个公司, 这个公司会出现在starred的列表里, 你可以导出这个列表, 可以导出csv或者xlsx
- 你可以自己添加这个行业的潜在用户, 这个用户默认被starred, 这样方便你管理
- 重新开始一次start research 会把你没有星标的, 也不是你添加的其他的公司刷新掉
Starred
这里就是所有你标记星标的用户, 方便你导出
Cases
这里我今天更新了
现在case会把上传的case里的公司信息, 和他们的需求提取出来, 当然你最好review一下, 如果有问题可以修改
case里的公司会被直接加到对应的行业里的公司列表里, 并且加星标
case里会把客户的需求提取出来, 然后自动去匹配你们的产品列表, 产品列表是从超擎的网站是爬下来的, 你也可以管理和维护, 比如:存储网络-OSFP 800Gb转2xOSFP NDR 400Gb 3m DAC, 这个会被映射到你们的DAC-800G
Product
这个下面你可以维护你们公司的产品, 目前是你们所有在网站上的产品, 他会自动匹配到用户的需求上去
Next Step
- 你需要告诉我更准确的你们筛选客户的逻辑
- 也要告诉我你们的cases是怎么帮助你们筛选客户的